Algorithm ที่ใช้ในการเปรียบเทียบ
✶ การค้นหาแบบลำดับ (Sequential Search)
✶ การค้นหาแบบลำดับ (Sequential Search)
คือการค้นหาข้อมูลจากชุดข้อมูลทีละรายการเรียงลำดับไปอย่างต่อเนื่องจนกว่าจะพบข้อมูลที่ต้องการ โดยเริ่มจากข้อมูลตัวแรกแล้วตรวจสอบไปจนถึงตัวสุดท้าย หากไม่ตรงกับค่าที่ต้องการค้นหาก็จะดำเนินการค้นหาตัวถัดไป อัลกอริทึมนี้มีความเร็วในการค้นหาเป็น O(n) เมื่อ n คือจำนวนรายการทั้งหมดในชุดข้อมูล
จุดเด่นของวิธีนี้คือ:
- ความง่ายในการใช้งาน ไม่จำเป็นต้องมีการจัดเรียงข้อมูลล่วงหน้า
- เหมาะสำหรับข้อมูลขนาดเล็ก หรือเมื่อต้องการตรวจสอบข้อมูลแบบเรียลไทม์
ในการค้นหาช่วงเวลาที่สูงสุดและต่ำสุดที่ลูกค้าใช้งานบนแพลตฟอร์ม การค้นหาแบบลำดับสามารถนำมาใช้เพื่อค้นหาช่วงเวลาที่มีจำนวนผู้ใช้งานสูงสุดและต่ำสุดได้ โดยผลลัพธ์จากการค้นหาจะมี 2 กรณีด้วยกันคือ:
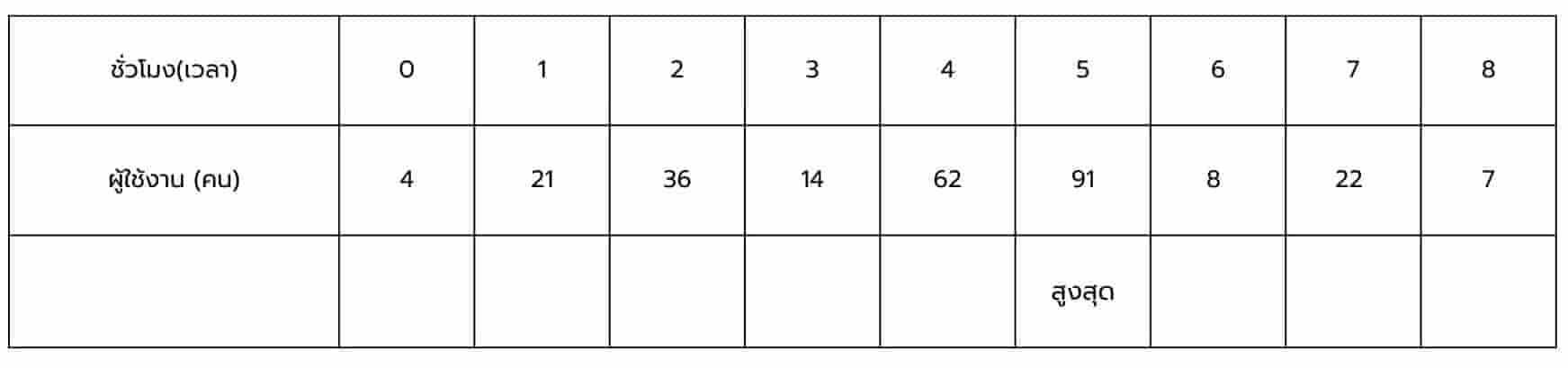
- พบช่วงเวลาที่มีการใช้งานสูงสุด
พิจารณาจากตารางต่อไปนี้ ในรอบแรกเรากำหนดให้ช่วงเวลาที่ดัชนี 0 มีจำนวนการใช้งาน 4 เป็นช่วงเวลาที่มีการใช้งานสูงสุด และทำการเปรียบเทียบกับช่วงเวลาถัดไป หากพบว่าช่วงเวลาใดมีจำนวนการใช้งานมากกว่าช่วงเวลาที่ถูกบันทึกไว้ จะทำการปรับปรุงช่วงเวลาที่มีการใช้งานสูงสุดใหม่ ทำเช่นนี้วนไปเรื่อย ๆ จนกระทั่งพิจารณาทุกช่วงเวลาแล้ว เราก็จะพบช่วงเวลาที่มีการใช้งานสูงสุด
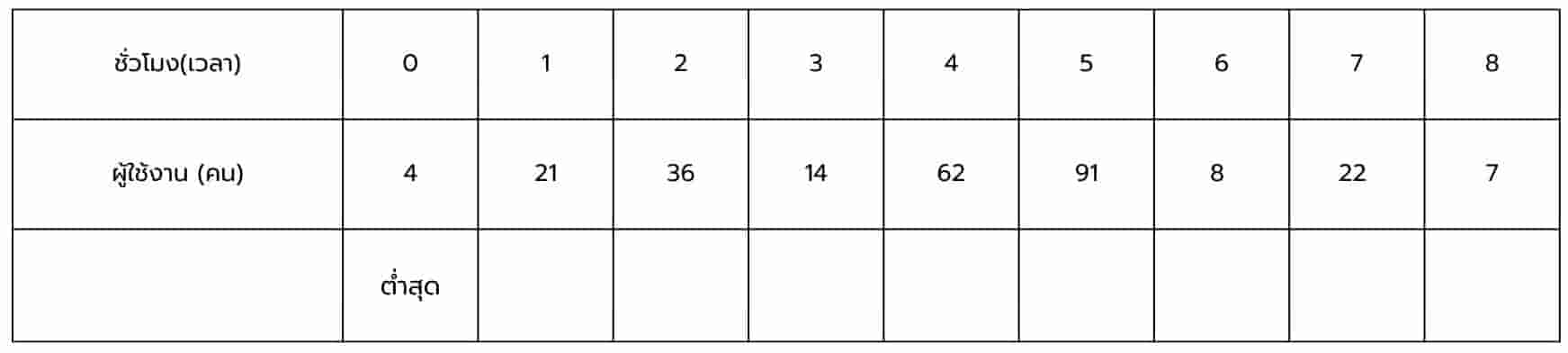
- พบช่วงเวลาที่มีการใช้งานต่ำสุด
โดยในรอบแรกเรากำหนดให้ช่วงเวลาที่ดัชนี 0 มีจำนวนการใช้งาน 4 เป็นช่วงเวลาที่มีการใช้งานต่ำสุด และทำการเปรียบเทียบกับช่วงเวลาถัดไป หากพบว่าช่วงเวลาใดมีจำนวนการใช้งานน้อยกว่าช่วงเวลาที่ถูกบันทึกไว้ จะทำการปรับปรุงช่วงเวลาที่มีการใช้งานต่ำสุดใหม่ ทำเช่นนี้วนไปเรื่อย ๆ จนกระทั่งพิจารณาทุกช่วงเวลาแล้ว เราก็จะพบช่วงเวลาที่มีการใช้งานต่ำสุด